Five separate systems. One badge. Here's how we orchestrated wake word detection, audio embeddings, LLM inference, and TTS into a seamless voice-activated experience-all within 8MB of RAM.
Taking our ESP32 LLM from prototype to our badge: Q8_0 quantization, inline PIE assembly achieving 16 int8 MACs per cycle, three-phase training, and SAM robotic TTS. This is where the badge gets its voice.
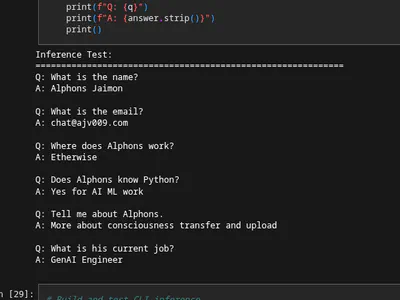
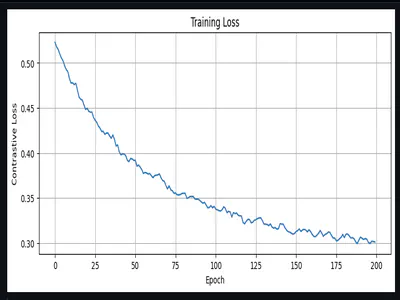
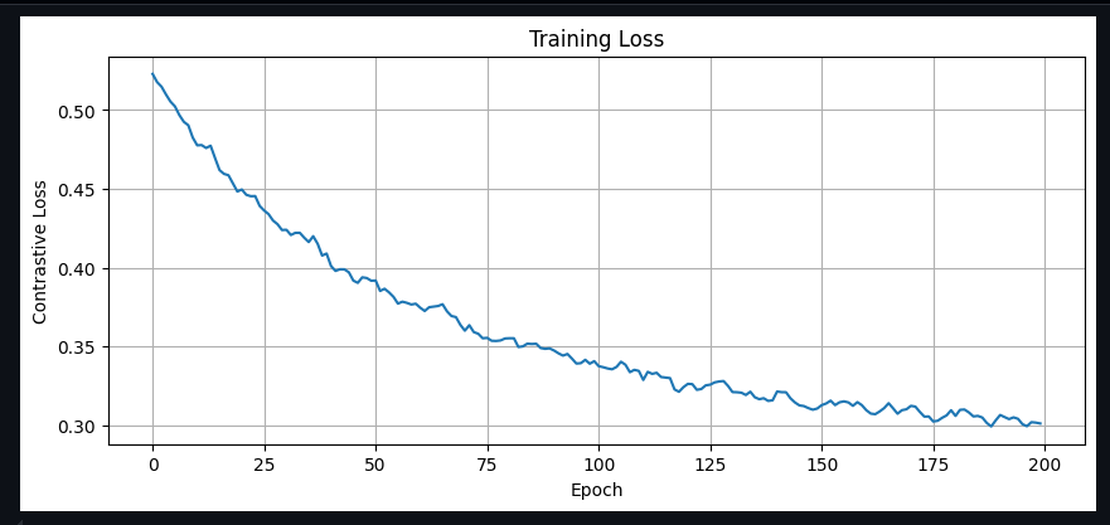
When Speech-to-Text models were too big for our 8MB PSRAM, we pivoted to a clever alternative: contrastive learning to match spoken audio directly to pre-embedded intents. Here's how we trained that system.
How we trained a custom 'Hey Daisy' wake word detector using confusable negatives, synthetic voice generation, and deployed it on ESP32-S3 with EdgeNeuron TFLite.
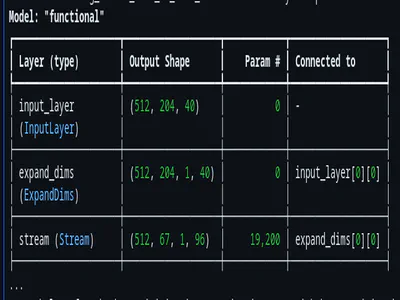
Deep dive into running a Large Language Model on an ESP32-S3 microcontroller - exploring llama2.c, SIMD optimizations, and the challenges of streaming inference on embedded hardware.
Exploring embedded video playback on ESP32-S3 with gyro-based auto-rotation. From MP4 to MJPEG conversion, PSRAM buffering, IMU integration, and building a smooth looping video player on a microcontroller.