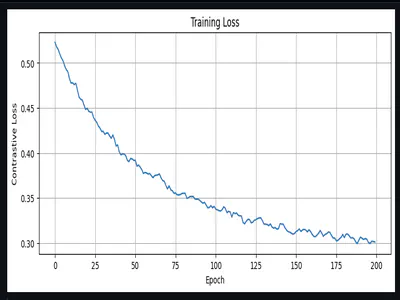
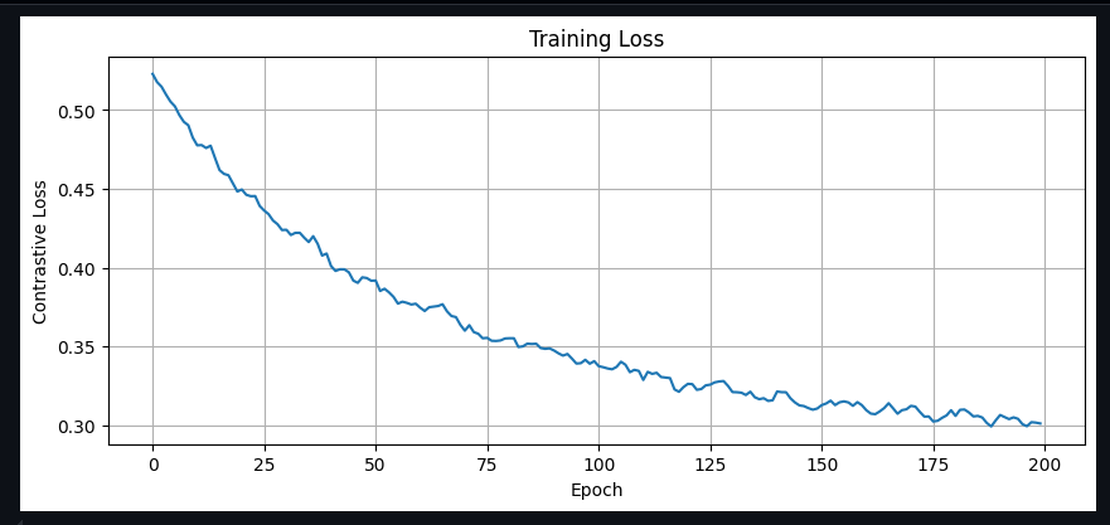
When Speech-to-Text models were too big for our 8MB PSRAM, we pivoted to a clever alternative: contrastive learning to match spoken audio directly to pre-embedded intents. Here's how we trained that system.