I had AI-assistance to craft an outline for this blog, to draft a version 0 based on all the possible context, flow, and structure, and finally as part of polishing phase I did read through this at least 2-3 times to edit, make tone changes, align better, removing and adding portions of text and code as needed. So if you see some parts of this article that seems a bit off or not aligned with the rest, it's probably because of that. I do my best to ensure quality and coherence. Please leave a message at [email protected] explaining what you found as too GenAI generated like, and if I find it worth something and if I make an edit based on that feedback I'll be happy to spare you a dollar. :)
The web as we know today is undergoing quiet some changes. Finally websites can utilize on-device AI capabilities without downloading GBs of there own model, yes and guess what Google Chrome Devs are pushing for it. They have proposed around 6-7 APIs that utilize the underlying AI capable hardware to run AI experiences and expose some essential tools for make interesting experiences without having to worry about the cost for simple practical use cases. No servers, no API keys, no data leaving your machine.
In this post, I’ll show you how I built a hybrid RAG (Retrieval-Augmented Generation) chatbot that routes queries between Chrome’s local Prompt API and a FastAPI RAG backend Server. A system that knows when to handle queries locally on-device versus when to reach out to more powerful cloud models.
Before we do any deeper dives into the code or demo, you should know a bit about the Chrome AI history just for the sake of it.
From Experiment to Web Standard
Google’s journey to bring AI directly into the browser began publicly at Google I/O 2024 in May, where they announced plans to integrate Gemini Nano, their efficient, on-device language model-directly into Chrome. The vision was to enable web developers to build AI-powered experiences without managing infrastructure, deploying models, or worrying about API costs.
By August 2024, Chrome launched several APIs into origin trials, opening up experimental access to developers worldwide. The Early Preview Program quickly attracted over 13,000 developers eager to explore this new API layer soon to be web standards. (Me and my team back in QED42 were part of the EAP as well, we explored occasionally but didn’t dive deep as its still something being slowly accepted and adopted by MDN and the web folks)
The momentum continued through 2024 and into 2025. Chrome 138, released in early 2025, marked a major milestone by bringing the Summarizer API, Language Detector API, Translator API, and Prompt API for Chrome Extensions into stable release. At Google I/O 2025 in May, Google expanded the offerings further with the Writer, Proofreader and Rewriter APIs entering origin trials, and unveiled multimodal capabilities for the Prompt API in Chrome Canary.
The Push for Web Standards
Chrome isn’t building these APIs in isolation. Google has actively engaged with web standards bodies to make on-device AI a cross-browser reality. The APIs have been proposed to the W3C Web Incubator Community Group, with several-including the Language Detector, Translator, Summarizer, Writer, and Rewriter APIs-already adopted by the W3C WebML Working Group.
Chrome has formally requested feedback from Mozilla (Firefox) and WebKit (Safari) through their respective standards positions processes. While explicit responses from other browser vendors are still pending, the standardization effort signals Chrome’s intent to make this a web-wide capability, not a proprietary feature.
For the latest updates and official documentation, visit:
Chrome’s AI capabilities span seven distinct APIs, each optimized for specific tasks:
Prompt API (Origin Trial / Stable in Extensions)
The most flexible of the bunch, a general-purpose interface to Gemini Nano for natural language tasks. Supports text, image, and audio inputs (multimodal in Canary). Perfect for classification, Q&A, content analysis, and any custom AI workflow. Some use cases are: Chatbots, content classification, semantic search, custom workflows and Query Routers.
Summarizer API (Stable in Chrome 138+)
Generates summaries in various formats: single sentences, paragraphs, bullet lists, or custom lengths. Ideal for condensing long articles, meeting transcripts, or user-generated content. Some use cases are: Article TL;DR, meeting notes and forum post summaries.
Writer API (Origin Trial)
Creates new content based on specified writing tasks and optional context. Can draft emails, reviews, blog posts, or any text from scratch. Some use cases are: Email drafting, content generation and writing assistance.
Rewriter API (Origin Trial)
Refines existing text by adjusting length or tone. Make content more formal, casual, concise, or elaborate. Some use cases are: Tone adjustment, text polishing and feedback improvement.
Proofreader API (Chrome Canary)
Grammar and style corrections for polished writing. Some use cases are: Writing quality checks and error detection.
Translator API (Stable in Chrome 138+)
Local language translation using expert models (not Gemini Nano). Some use cases are: Multi-language support and accessibility.
Language Detector API (Stable in Chrome 138+)
Identifies the language of text input. Some use cases are: Auto-detection for translation and content routing.
Each API is task-specific and optimized for its domain. But here’s the thing: the Prompt API stands apart.
Prompt API for custom Prompting a Simple Query Router
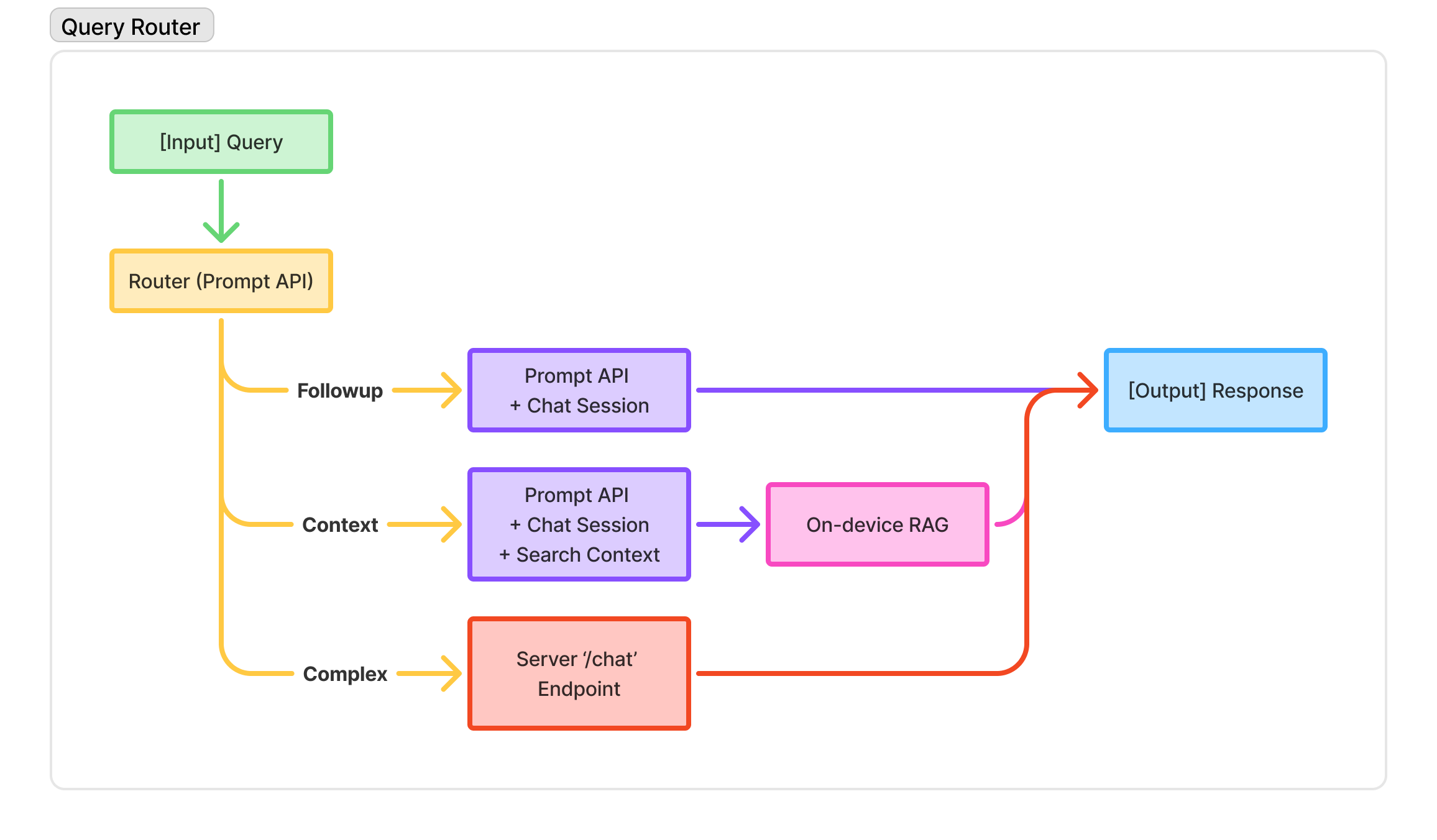
The flexibility of the Prompt API makes it perfect for contextual query routing a use case that’s both practical and underutilized. Instead of blindly sending every query to an expensive cloud API or handling everything with a constrained on-device model, you can create a hybrid system that:
Uses Prompt API to classify the query (simple vs. complex)
Routes simple queries to on-device processing (fast, free, private)
Routes complex queries to powerful cloud models (when needed)
This is the architectural pattern we’ll explore in depth.
Before diving into the implementation, let’s look at the data: why does routing matter?
The Economics of Query Routing
Recent research reveals that query routing isn’t just a nice-to-have-it’s transformational for cost, performance, and user experience. Here’s what the data shows:
Not all queries are created equal. In real-world conversational AI deployments, the vast majority of queries are simple-and perfect candidates for on-device routing.
Query Type
% of Total
Complexity
Ideal Route
Greetings & pleasantries
15-20%
Trivial
On-device (Prompt API)
Simple follow-ups
25-30%
Low
On-device (Prompt API)
FAQ-style questions
30-35%
Low-Medium
On-device with context
Analytical queries
10-15%
High
Cloud API
Multi-step reasoning
5-10%
Very High
Cloud API
What you see right there is a massive more than 50-60% of cost reduction if implemented right.
Why This Matters for Our little Medical RAG
Applied to our medical knowledge chatbot:
Follow-up queries (“Can you elaborate?”) → ~30% of interactions → 100% on-device
Simple context queries (“What is the heart?”) → ~40% of interactions → On-device with local RAG
Complex queries (“Compare complications…”) → ~30% of interactions → Cloud API
Expected outcome: ~70% of queries handled on-device, saving 70%+ on API costs while improving latency and privacy.
The Idea: A Hybrid RAG Chat Router
Traditional RAG systems are all-or-nothing: every query goes through the same pipeline-vector search, context injection, LLM generation. But not all queries need the full treatment.
Consider these questions to a medical knowledge chatbot:
“What is the heart?” → Needs context from the knowledge base, but straightforward
“Can you elaborate on that?” → Just needs conversation history, no retrieval
“How do complications of diabetes interact with hypertension in elderly patients?” → Complex, needs deep retrieval and powerful reasoning
So therefore comes the Three-Tier Routing Strategy
I designed a little system that classifies user queries into three categories and routes them accordingly:
The three-tier routing strategy I’ve implemented somewhat aligns with the internet version of what the broader AI community now calls Adaptive RAG. After I build this demo, I realized the pattern wasn’t unique-it’s part of a larger-longer list of context-aware retrieval systems.
After the initial implementation, I did some research on adaptive RAG patterns, and it turns out our approach hits several key scenarios that are becoming industry standards:
Common Adaptive RAG Scenarios
1. Query-Based Routing
The most fundamental pattern-analyzing queries and routing to different strategies:
No retrieval when the LLM already knows the answer (our “followup” category)
Single-shot RAG for straightforward queries (our “context” category)
Iterative RAG for complex, multi-step queries
Web search for queries outside the knowledge base (our “complex” category using cloud API)
2. Multi-Source Routing
Acting as a smart router that chooses the best retrieval tool:
Vector databases for semantic search (our FAISS implementation)
SQL databases for structured data
Knowledge graphs for relational queries
Live web search for current information
External APIs and sources
3. Agentic Decision-Making
Using autonomous agents that:
Evaluate retrieval quality in real-time
Decide whether to rephrase queries
Switch sources mid-retrieval
Stop when context is sufficient
Self-correct and refine results
4. Self-Reflective RAG (Self-RAG)
Systems that dynamically:
Decide when to retrieve (not always necessary)
Evaluate relevance of retrieved data
Critique their own outputs
Trigger re-retrieval if quality is low
5. Corrective RAG
Adaptive systems that:
Verify accuracy of retrieved documents
Filter out irrelevant results
Request additional retrieval when quality is low
Fallback to alternative sources
6. Query Intent Classification
Routing based on query type (exactly what our router does):
Technical queries → documentation/code repos
Factual queries → knowledge bases
Comparative queries → multi-document retrieval
Procedural queries → step-by-step guides
How Our Implementation Fits
Our hybrid RAG router implements #1 (Query-Based Routing) and #6 (Query Intent Classification) explicitly, using Chrome’s Prompt API as the classification layer. The good part is that we get:
High cost reduction by keeping simple queries on-device
Privacy preservation for follow-up conversations
Sub-second latency for non-complex queries
Seamless escalation to powerful cloud models when needed
The key insight across all these patterns: Adaptive RAG moves from static “always retrieve the same way” approaches to dynamic decision-making where the system evaluates each query’s characteristics and adapts its strategy accordingly.
This isn’t just about cost savings (though that’s significant). It’s about building smarter systems that understand when to use expensive resources and when simpler approaches suffice-much like how humans naturally decide when to “look something up” versus answering from memory.
Implementation Deep Dive
Am not gonna document the whole backend code, its a simple RAG not that fancy or anything, in fact its too basic. but you can visit (Github) Chrome AI Demo
The whole demo was vibe coded sort of. I barely touched the code. (I did make some minor changes in structure and decisions that Claude made which I did not include in there)
Following is the prompt for the Python FastAPI:
So here I have done a uv init, its an empty project at the moment BUT I want you to you an API for the following:
Its a very simple RAG API, by simple I mean no unnecessary error handlers and such, very simple, I need to use the code for a demo blog thing so no complications as such.
In fact the RAG background should be just copied from this notebook here, its another utter simple RAG here @/home/alphons/project/OAISYS25/chrome_ai_demo/workbench/rag_synth.ipynb its just a reference to show how simple it could be.
for the vector database use something simple as FAISS BUT see that a file or some bin or some dumb is created locally AFTER all the documents are indexed into it because I don't want to re-index everything just because I restart the app, okay?
Now for the embedding model it would be a sentence transformer model but please for gods sake try NOT to download any nvidia libraries and stuff that comes as dependencies, they take GBs and endless times to download.
I guess its something like installing just the cpu versoin of torch first and then later installing sentence transfer and also setting device as cpu
`pip install torch --index-url https://download.pytorch.org/whl/cpu` (adapt to uv command as needed)
as for the model lets try this one: https://huggingface.co/sentence-transformers/embeddinggemma-300m-medical its a medical finetune of embeddinggemma-0.3b, its a new model and its around 1.3/4gb or so, YEs it will be slow on CPU but its okay, we are just creating a demo a>
Next is the chunking method, use a basic paragraph based chunking, no libraries needed as such, lets just do it manually detecting new lines and all.
A quick note on chunking:
When storing to the vector database create ids like this: doc_id_1_chunk_id_1, doc_id_1_chunk_id_2, doc_id_2_chunk_id_1, doc_id_2_chunk_id_2
Hope you got that pattern I'll tell you why we need that in a moment soon as I explain the RAG endpoints.
And as for the data set lets use https://huggingface.co/datasets/zxvix/MedicalTextbook its a data with text column filled with rows of TEXT about basic things. Don;t index complete database, just first 10 rows are enough.
And for inferencing we will use the same OpenRoute model and the way we are accessing it through openai library as seen in the previous notebook that I attached to you.
Now finally we will have 2 very important endpoints as following coming out of this FastAPI implementation:
"/search"
This is basically your vector search sort of thing.
Text in :: chunks out
"/chat"
this is your basic RAG chat thing, but the structure of this will be almost similar to OpenAI endpoints. WE WILL NOT store any history in the API instead we already sent an array of message as we usually do for such chatbots.
messages: [
{
"role": "system",
"content": "some_content"
},
{
"role": "user",
"content": "tell me about xyz"
},
{
"role": "assistant",
"content": "xyz means abc and so on"
"chunks_referred": [
{
"id": "doc_id_3_chunk_id_4",
"content": "long text"
},
{
"id": "doc_id_2_chunk_id_5",
"content": "long text"
}
]
},
{
"role": "user",
"content": "Oh thanks, that sounds nice"
},
]
Now you might think how will the rag work in this case, so we pick the last element of the message array thats sent in, in this case the "oh thanks ..." and then do a quick retrieval on my function powering the search endpoint.
then pass it to the our openrouter api thing. note that since openrouter wont support custom params like "chunks_referred" don't send that into the openrouter api
The response need not be a streaming one for now. Since these are small models we will get the requires response quick so no worries there as well.
And a few more things to keep in mind:
- No need to write data models and stuff for the API, like I said this is a quick learning demo app.
- BUT yeah keep the logic code and stuff out of the routes file, every major action / function should be kept in a separate like how folks structure large projects, even tho this is not large keeping each file line of code to less than 100 lines would be much cleaner and >
I move all the uv init files to @api folder, we will use that folder from now on.
Now ultrathink, and first propose me a plan before coding anything.
Next is the Prompt for the site:
Now next we need to create a very simple html + js + css site.
It would be a static site, no complex js frameworks OR anything.
we will create this in the empty @web folder here
Add a simple multi turn chat UI, no need for session managing and services and so on.
Keep the JS part dedicated into its own js file, I mean specifically the inference one and well make it talk with the python api that we just created.
btw keep the UI too very simple, like a multi-turn chat window in the middle, thats pretty much it.
And finally integrating the Chrome AI - Prompt API into it:
Now we need to implement the Chrome API.
SO right now in this system I don't have access to WebGPU and therefore it wont work here but once you write the code I can test it on my secondary system which I previously already tested the demo sites of this new Chrome API.
So this is a very new API thing that Chrome is pushing for as web standards, so I need you to first do a bit of web search and study about Chrome in-built / on-device AI APIs.
We will be focusing specifically on the Prompt API here for our use case.
And here are some PDF copies of the documentations if you need:
1. @"workbench/developer.chrome.com-Get started with built-in AI.pdf"
2. @"workbench/developer.chrome.com-The Prompt API.pdf"
(Also my origin trials token can be found in ".origin_trail_token" in the workbench folder)
Now I will get down to our use case and idea properly here:
Am planning to use this like a prompt router / gateway sort of thing.
1. So when the user inputs there message in the chatbot (the chatbot can be found in the @web folder, as you can already see we have tried to keep all the code very slim, and simple as this is a demo app)
2. We will have a separate few-shot array of message for the "query_router".
The query_router thing will sort of classify the prompts into following buckets based on there types:
2.1 Follow up queries: "Oh, can you elaborate please" or "Ahh I see, whats the deal with xyz in there tho"
These need no calling to our python API, instead we send the same message array of user/assistants to the Prompt API itself
2.2 Needs more Context AND not complex or too simple to answer: "ok what does abc mean then" or "help me understand abc along with xyz"
So here mentioning any topic or keywords and such in the query mean that we need more context to answer, so we ping the /search endpoint (you can refer that in @api/routes.py) and then similar to how the rag works in @api, we simulate the behavior in the Prompt API itself.
2.3 Complex query: "Can you help me understand the complications of pqr in conjunction with xyz'
Just avoid using Prompt API in this case and route the query to the python endpoint.
---
Few things to keep in mind:
1. the docs suggest that we should implement error handlers and fallbacks and so on, but my whole objective here is to just implement this and use it on a supported platform directly
2. if it doest work THEN it doesn't work thats it, no fallbacks, no unnecessary try catch and stuff and so on.
3. This is a demo application so I just need it working ONE SINGLE TIME just to take a video explaining it and so on, so that Later I can blog post this whole experiment / demo thing.
4. So yeah all of this means that when writing code, just assume things need to work so no over-complications or unnecessary abstractions for future and so on, this will be pretty much the last version of this demo.
---
Alright now instead since I cannot do like a iterative development and test at the moment I need you to ultrathink, take time to think through and plan the whole thing before making any code changes, you will need to propose me the complete implementation plan after you think through the complete thing. And then i'll decide /modify and so as needed.
Thats pretty much, the demo was up within 45mins tested and working, mostly single-shot. Thanks to Sonnet 4.5 through Claude Code.
Backend: Python RAG API
The backend is a FastAPI service with:
FAISS vector index for similarity search
embeddinggemma-300m-medical A fine-tuned sentence-transformers embedding model (randomly picked from HuggingFace)
OpenRouter for cloud LLM inference (meta-llama/llama-3.3-8b-instruct)
Two endpoints:
GET /search - Returns top-k relevant chunks for a query
POST /chat - Full RAG pipeline with streaming response
This backend runs on localhost:8000 and handles complex queries.
Frontend: Query Router
This happens in web/chat.js. Here’s how it works:
1. Initialize Two Prompt API Sessions
// Router session: Classifies queries
routerSession=awaitLanguageModel.create({
initialPrompts: [{
role:'system',
content:`You are a query classifier. Classify queries into:
1. "followup": Refers to previous conversation
2. "context": Asks about specific medical topics
3. "complex": Requires deep analysis or comparisons
Respond with JSON: {"category": "followup"|"context"|"complex"}` }]
});
// Chat session: Handles conversations
chatSession=awaitLanguageModel.create();
4+ GB VRAM (GPU) or 16 GB RAM + 4 CPU cores (CPU mode)
Desktop OS (Windows 10/11, macOS 13+, Linux, ChromeOS on Chromebook Plus)
Not all users will have compatible devices. Mobile support is not yet available.
And yeah am not a windows user but only my windows computer had the said VRAM easy to use.
Model Capabilities
Gemini Nano is optimized for on-device efficiency, not accuracy at all costs. It’s not a replacement for GPT-4 or Claude. Complex reasoning, factual accuracy, and long-context tasks are better suited for cloud models-hence our routing strategy.
Gated model and missing LoRA support
Its Gemini Nano still closed source, would have been better if they just used a Gemma model and also opened a LoRA API which would have allowed folks to have tiny 25-100 MBs of fine-tunes that would allow folks to target more niche use cases, like Generative UI for local and so on.
In the early documentation they had mentioned of a LoRA fine tune APIs, but then it later got scrubbed off the documentations, I assume they are pivoting or changing some plans around it.
I tried doing something tho, or more like my original vision or idea for this blog was different:
No am not the first person trying to reverse engineer and find the underlying model details, I was inspired by this guy here https://huggingface.co/oongaboongahacker/Gemini-Nano. He was able to find the Model and even display its stats and stuff.
Also no am not an expert in this field either. I just like exploring and doing whatever seems fun to pursue.
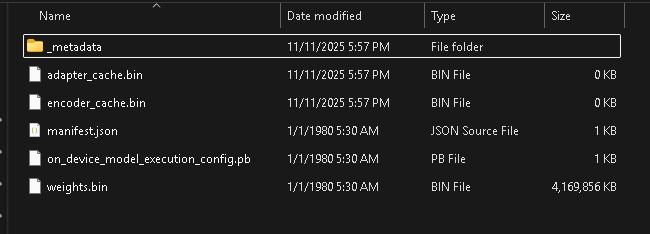
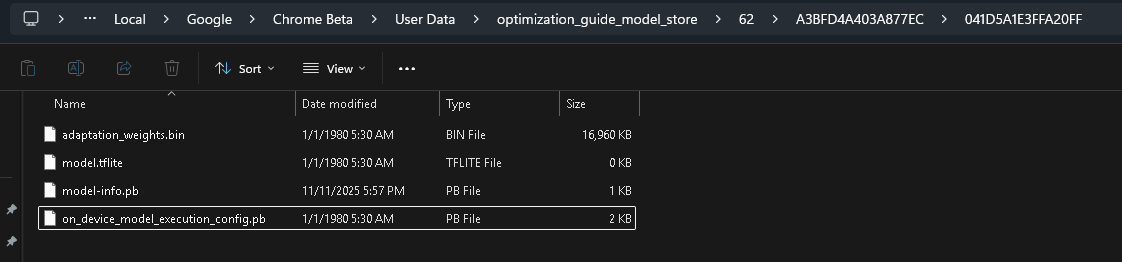
His post is from an year ago, and the model and fine-tune files which I found in my local were quite big:
And a LoRA file as well, this is probably related to the Summarizer API, because I had test run it from Chromes Demo Page
So my other idea was something like this:
Expose the model path to a browser extension.
This browser extension would expose an API, will call it a fine-tune or LoRA API
Websites can simply load there 10-100MBs of LoRA fine-tunes on the site and load them on top of the existing Chrome Model
Sounds easy right? But it wasn’t, so many blockers along the way:
There was only a bin file of the model, no idea what tokenizer and stuff it used, no detailed idea on the architecture, am pretty sure some skilled person with deeper ML knowledge would be able to help me with that, but yeah until then I/we would have no idea how to really train something for it. (actually on later reading of the claude logs I realized there was a way, but anyways keeping that fact aside for the time being)
The in-built LoRA file was an un-readable file, while the model weights.bin was debuggable using mediapipe / tflite tools
Lets imagine we figured out LoRA, Chromes filesystem protection doesn’t allow to load any file from protected folders or system folders, in other words folders that usually need higher permissions to manipulate, which is where our source weight.bin file located.
So then I learned one could create something called as Native Host which is an application to be installed on the computer which can then communicate with an extension or API or something in the browser. (read more in the above hyperlinked ‘Native Host’) Now this whole thing became complicated, I was able to get the model but now I was stuck on the fine-tune part.
Honestly if Google opens a path to Fine-Tune API, imagine the use cases: You obviously cannot prompt your way into niche cases like outputting specific design language or language itself, structures, hardened outputs and so on. And LoRA are just as small and big as bundles of JS libraries, this would fundamentally change the web AI scene if Google does this right. Also making GenAI when smartly done affordable for smaller companies and organizations that wanna give this GenAI experience without breaking there banking on serving requests.
I didn’t stop at this, I got a full clone of the chromium project (Stupid me I forgot it would include all the device chrome build tools and everything on the planet)
When expanded it went to roughly ~110GB on disk.
And then I explored it a bit and also assigned Claude Code to crack the model loading logic and not stop until it found a way with my original goal and idea. So yeah it went on for very long-long sessions of more than 1000+ messages, I mean the repo is stupid big and finding good leads did take time.
Here is a quick summary of the findings I generated from Claude itself through the chat history:
This is a complete AI generated document here, even I haven’t personally verified it as such, it just seemed interesting.
// Chrome's Component Updater downloads:
// - Base model weights (weights.bin)
// - Sentencepiece model (for tokenization)
// - Cache files (optional, for acceleration)
// - Manifest with version info
void OnDeviceModelServiceController::Init() {
// Register for base model availability
base_model_asset_manager_ = std::make_unique<OnDeviceAssetManager>(model_provider_);
// Wait for component to be ready
base_model_asset_manager_->AddObserver(this);
}
What prolly happens inside (proprietary libchrome_ai.so):
1. Parse TFLite model from weights_file
2. Initialize GPU/APU backend
3. Allocate weight cache memory
4. Load weights into GPU/memory
5. Prepare tokenizer (sentencepiece)
6. Initialize LoRA infrastructure (empty initially)
7. Return opaque model handle
2. LoRA Adaptation Loading Flow
2.1 High-Level Overview
Feature Usage → Adaptation Loader → Model Compatibility Check → Session Creation
↓ ↓ ↓ ↓
Summarizer Fetch LoRA from Check base model Apply LoRA
API called model store version & hints to session
void OnDeviceModelAdaptationController::MaybeRegisterAdaptation(
ModelBasedCapabilityKey feature,
bool was_recently_used) {
// Check if base model is ready
if (!base_model_available_) {
return;
}
// Get base model spec
const OnDeviceBaseModelSpec& spec = GetBaseModelSpec();
// Register for adaptation download
adaptation_loader_map_->MaybeRegisterModelDownload(
feature, spec, was_recently_used);
}
void SessionAccessor::CreateInternal(
on_device_model::mojom::SessionParamsPtr params,
on_device_model::mojom::LoadAdaptationParamsPtr adaptation_params,
std::optional<uint32_t> adaptation_id) {
// Prepare base descriptor
ChromeMLAdaptationDescriptor descriptor = {
.max_tokens = params->max_tokens,
.top_k = params->top_k,
.temperature = params->temperature,
.enable_image_input = params->capabilities.image_input,
.enable_audio_input = params->capabilities.audio_input,
.model_data =nullptr// Will be set below if LoRA present
};
ChromeMLModelData data;
std::string weights_path_str;
// ⭐ IF ADAPTATION IS PRESENT
if (adaptation_params) {
weights_path_str = adaptation_params->assets.weights_path.AsUTF8Unsafe();
if (adaptation_params->assets.weights.IsValid() ||!weights_path_str.empty()) {
// GPU backend: use file handle
if (adaptation_params->assets.weights.IsValid()) {
data.weights_file = adaptation_params->assets.weights.TakePlatformFile();
}
// APU backend: use file path
else {
data.model_path = weights_path_str.data();
}
data.file_id = adaptation_id; // For caching
descriptor.model_data =&data; // ⭐ ATTACH LORA DATA
}
}
// ⭐ CREATE SESSION with base model + optional LoRA
session_ = chrome_ml_->api().CreateSession(model_, &descriptor);
}
Step 6: Native Library LoRA Application
What prolly happens inside libchrome_ai.so (proprietary):
CreateSession(model, descriptor):
1. Clone base model state
2. IF descriptor.model_data != NULL:
a. Read adaptation_weights.bin into memory
b. Parse binary format (proprietary)
c. Extract LoRA A/B matrices
d. Apply LoRA to attention layers:
- For each layer:
- Original: W
- LoRA: ΔW = B × A (rank reduction)
- Modified: W' = W + α × ΔW
e. Update session weights
3. Initialize tokenizer state
4. Allocate context buffers
5. Return session handle
Chrome’s AI loading system is a multi-layered architecture:
Component Updater → Downloads models
Optimization Guide → Manages model lifecycle
Model Executor → Creates model instances
Session Accessor → Applies LoRAs
Native Library → Does actual ML inference
The critical discovery is that LoRA weights are passed as raw file handles to the proprietary native library, which parses the binary format internally. Our testing framework targets this format to enable custom LoRA loading!
Back to reading about other hurdles on Chrome AI API
Context Window Limits
On-device models have smaller context windows. For very long conversations or large context injections, you may hit limits. The routing logic helps by keeping complex cases on cloud models. But you still would need a logic to keep the context within size, like rolling windows or trimming unnecessary context over time.
Browser Compatibility
This only works in Chrome 138+. Cross-browser support depends on standardization progress and other vendors adopting the APIs. (Opera is the only other browser that supports this I guess, since its also based on Chrome)
Looking Forward
Chrome’s built-in AI APIs are still experimental, but the trajectory is clear: on-device AI is becoming a web platform primitive. As standardization progresses and browser support expands, we’ll see patterns like intelligent query routing become standard practice.
Imagine a future where:
Static sites have AI features without backend costs (Like mine, am working on it for fun)
Privacy-first AI is the default, not an exception
Hybrid architectures seamlessly blend on-device and cloud intelligence
Every website can offer personalized, context-aware experiences complete on-device and local
We’re in the early innings, but the potential is enormous. Thanks for reading!
During this exploration I was parallely exploring and intrigued by dozens of routing techniques used by different organizations and companies and it was quite interesting to be honest. I’ll be writing a blog around it soon. Follow me on LinkedIn to know about it.